
تصور کنید وارد یک فروشگاه آنلاین بزرگ مثل دیجیکالا یا آمازون میشوید. همزمان هزاران نفر دیگر هم درحال خرید هستند، بعضیها به دنبال گوشی، بعضیها لپتاپ، بعضیها هم به دنبال لباس هستند. حالا همه این درخواستها باید از یک پایگاه داده پردازش شوند. نتیجه چی میشود؟ کندی شدید، خطا و حتی Down شدن سیستم. اینجاست که مفهوم Database Sharding به کمک میاد؛ روشی برای تقسیم هوشمندانه دادهها تا بتوانیم میلیاردها درخواست را همزمان مدیریت کنیم. در این مقاله از دواپس ایران این موضوع را بررسی میکنیم با ما همراه باشید.
با ترکیب خدمات دواپس و امنیت شبکه، از دسترسی غیرمجاز جلوگیری کرده و ثبات عملیاتی سیستمهای خود را تضمین کنید. درخواست مشاوره تخصصی ثبت کنید تا کارشناسان دواپس ایران بهترین راهکار را برای ساختار شبکه شما پیشنهاد دهند.
Database Sharding چیست؟
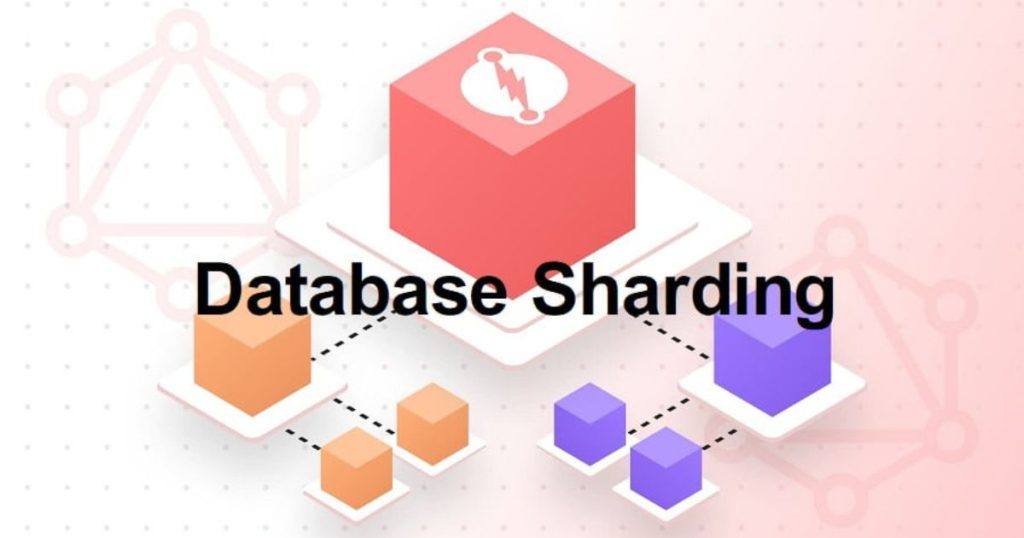
Database Sharding روشی در معماری پایگاه داده است که در آن یک پایگاه دادهی بزرگ به چند بخش کوچکتر و مستقل به نام Shard تقسیم میشود. هر Shard تنها بخشی از دادهها را ذخیره میکند و میتواند روی سرور جداگانهای قرار گیرد. این کار باعث میشود که بار پردازشی میان چند سرور توزیع شود، سرعت پرسوجوها (Query) افزایش یابد و مقیاسپذیری سیستم بهبود پیدا کند. Sharding بهویژه در سیستمهایی با حجم بسیار زیاد داده و تعداد بالای کاربران، یک راهکار کلیدی محسوب میشود. سرور چیست؟ سرور یک کامپیوتر قدرتمند و همیشه روشن است که منابع، دادهها یا خدماتی را در اختیار سایر کامپیوترها و کاربران (کلاینتها) قرار میدهد.
به مثال زیر توجه کنید:
فرض کنید یک شبکهی اجتماعی بزرگ دارید که میلیونها کاربر دارد. اگر همهی اطلاعات کاربران در یک پایگاه داده ذخیره شود، حجم داده بسیار زیاد شده و سرعت سیستم کاهش مییابد. برای حل این مشکل میتوان کاربران را بر اساس شناسه (UserID) تقسیم کرد؛ مثلاً کاربرانی با شناسه ۱ تا ۵۰۰ هزار در Shard اول، کاربران ۵۰۰ هزار تا یک میلیون در Shard دوم و همینطور ادامه. در این حالت، هر Shard بخشی از دادهها را مدیریت میکند و بار کاری بین چند پایگاه داده تقسیم میشود.
چرا به Sharding نیاز داریم؟
Database Sharding پاسخی عملی به محدودیتهای ذاتیِ پایگاهدادههای متمرکز است؛ زمانی که حجم داده، تعداد تراکنشها یا ضرورت توزیع جغرافیایی فراتر از توان یک سرور یا یک خوشهی ساده میرود، شاردینگ اجازه میدهد بار کاری، ذخیره و پاسخدهی بهصورت همزمان و مؤثری توزیع شود. در عمل Sharding نه تنها کارایی و مقیاسپذیری را ارتقاء میدهد، بلکه قابلیت دسترسپذیری، ایزولاسیون خطا و انطباق با الزامات محل نگهداری دادهها (data locality) را نیز بهتر میکند.
محدودیتهای معماری متمرکز
یک پایگاهدادهی متمرکز بالاخره با محدودیتهای فیزیکی روبهرو میشود: CPU، حافظه (RAM)، پهنای باند ورودی/خروجی دیسک و پهنای باند شبکه. افزایش این منابع (Vertical Scaling) تا حدی ممکن است، اما هزینهبر، دارای سقف عملی و در نهایت غیرقابلاتکا برای رشد نامحدود است. علاوه بر این، گلوگاه روی یک نقطه واحد (Single Point of Failure) ریسک کلی سرویس را بالا میبرد. همین چالشها زمینهساز حرکت به سمت معماری میکروسرویس ها و الگوهایی مانند Database Sharding شدند که با توزیع داده و سرویسها، مقیاسپذیری و پایداری سیستم را افزایش میدهند.
مقیاسپذیری افقی و کنترل هزینه
شاردینگ امکان مقیاسپذیری افقی (horizontal scaling) را فراهم میآورد: بهجای ارتقای یک سرور بزرگ، میتوان چند سرور متوسط اضافه کرد و داده را بین آنها تقسیم نمود. این مدل اغلب از منظر هزینه و نگهداری معقولتر و قابل رشدتر است، زیرا میتوان ظرفیت را به مرور و بر اساس نیاز افزایش داد.
افزایش کارایی و کاهش تأخیر
با توزیع دادهها و پردازش بین چند Shard، هر پرسوجو معمولاً به مجموعهی کوچکتری از دادهها دسترسی دارد. این موضوع موجب کاهش زمان پاسخ (latency) و افزایش توان عملیاتی (throughput) میگردد، بهویژه در سیستمهایی که همزمانی بالاست.
مقیاسپذیری نوشتن (Write Scalability)
Replication معمولاً خواندن (reads) را تسریع میکند، اما برای بارهای نوشتن (writes) چندان کمککننده نیست؛ تمام replicaها باید بهنحوی هماهنگ شوند. اگر بار نوشتن زیاد باشد، تنها راهکار واقعی تقسیم دادهها (sharding) است تا نوشتنها میان چندین node توزیع شود و هر node مسئول بخشی از ترافیک نوشتن شود.
دسترسپذیری و ایزوله کردن شکستها
در صورت بروز مشکل در یک Shard، سایر Shardها میتوانند به کار خود ادامه دهند؛ بنابراین خرابی یک بخش به معنی قطع کامل سرویس نیست (البته بسته به طراحی application ممکن است برخی توابع محدودهای از کار بیفتد). این ایزولاسیون خطا به بهبود قابلیت بازیابی و کاهش اثرات خرابکاری یا بار ناگهانی کمک میکند.
توزیع جغرافیایی و انطباق با مقررات
برای سرویسهای جهانی، نگهداری دادهها نزدیک به کاربران (data locality) باعث کاهش تأخیر و بهبود تجربه کاربری میشود. همچنین برخی قوانین و مقررات (مثلاً حفاظت دادههای شهروندان) ایجاب میکنند دادهها داخل یک منطقه جغرافیایی مشخص نگهداری شوند؛ شاردینگ میتواند دادهها را بر اساس منطقه توزیع کند تا هم عملکرد و هم تطابق قانونی تأمین شود.
ایزولاسیون بار کاری و چندمستاجری (Multi-tenancy)
در سیستمهایی که چند مشتری (tenant) یا چند نوع سرویس وجود دارد، شاردینگ اجازه میدهد بار هر مشتری بهصورت منطقی جدا شود (مثلاً هر مشتری یک Shard یا مجموعهای از Shardها داشته باشد). این کار مدیریت ظرفیت، صورتحساب و بازیابی را سادهتر میکند.
نگهداری، بهروزرسانی و عملیات بدون قطعی
شاردینگ فرآیندهای نگهداری و بهروزرسانی را قابل مدیریتتر میکند؛ مثلاً میتوان یک Shard را جداگانه بهروزرسانی یا بازسازی کرد بدون آنکه کل سیستم از کار بیفتد. این موضوع بهویژه در سرویسهای با SLA سختگیرانه اهمیت دارد.
مثالهایی از این موضوع:
- فروشگاه اینترنتی در روزهایی مانند «جمعه سیاه»: رشد لحظهای در تعداد سفارش و تراکنشها که بدون تقسیم بار و توزیع داده قابل مدیریت نیست.
- شبکه اجتماعی: تعداد زیاد بهروزرسانیها (پست، کامنت، لایک) که نیاز به توزیع نوشتن دارد تا از گلوگاه نوشتن جلوگیری شود.
- سامانه بانکی بینالمللی: نیاز به نگهداری دادهها در مراکز دادهی نزدیک به هر کشور برای کمینهسازی تأخیر و رعایت قوانین محلی.
بیشتر بخوانید: SQL Injection: روشهای جلوگیری از آسیبپذیریهای امنیتی
چه زمانی باید به شاردینگ فکر کرد؟ (چکلیست تصمیمگیری)
- مقدار داده و رشد آن طوری است که دیگر در یک سرور یا خوشهی ساده جا نمیگیرد یا کارایی لازم را ندارد.
- توان نوشتن (write throughput) به سطحی رسیده که replication و caching کافی نیست.
- تاخیر پاسخدهی برای کاربران در برخی مناطق جغرافیایی غیرقابلقبول است.
- نیاز به جداسازی منطقی دادهها بین مشتریان یا سطوح سرویس وجود دارد.
- هزینه یا ریسک ارتقای عمودی (vertical scaling) نامطلوب یا غیرعملی است.
محدودیتها و هزینههای شاردینگ
شاردینگ راهکار قدرتمندی است، اما به قیمت افزایش پیچیدگی: مدیریت توزیع داده، بازتوازن (Rebalancing)، اجرای پرسوجوهای چندShard، تراکنشهای توزیعشده و مانیتورینگ پیشرفته با ابزارهایی مانند Zabbix و Grafana از جمله چالشهایی هستند که باید در طراحی لحاظ شوند. بنابراین، پیش از تصمیمگیری برای پیادهسازی Sharding، بهتر است ابتدا بهینهسازیهای سادهتر مانند Caching، بهبود ایندکسها، استفاده از Read-Replicas و ارتقای لایهی سختافزار را بررسی کنید.
روشهای Sharding
Sharding را میتوان به روشهای مختلفی پیادهسازی کرد. هر روش مزایا و معایب خاص خودش را دارد و انتخاب درست بستگی به نوع داده، الگوی دسترسی، میزان رشد سیستم و اهداف مقیاسپذیری دارد. در ادامه مهمترین روشهای Sharding را توضیح میدهم:
Sharding مبتنی بر Range (Range-Based Sharding)
در این روش دادهها بر اساس بازههای مشخصی از یک کلید (معمولاً شناسه یا تاریخ) تقسیم میشوند.
- کاربران با شناسه ۱ تا ۵۰۰ هزار در Shard اول، شناسه ۵۰۰ هزار تا یک میلیون در Shard دوم، و همینطور ادامه.
Sharding مبتنی بر Hash (Hash-Based Sharding)
در این روش، روی کلید اصلی (مانند UserID) یک تابع Hash اعمال میشود و نتیجه تعیین میکند که داده در کدام Shard ذخیره شود.
- تابع Hash روی شناسه کاربر عددی تولید میکند و بر اساس باقیمانده تقسیم بر تعداد Shardها، مکان داده مشخص میشود. مثلاً UserID % 4 مشخص میکند کاربر در Shard 0 تا Shard 3 قرار گیرد.
Sharding مبتنی بر Directory (Directory-Based Sharding)
در این روش یک جدول مرجع (Directory) وجود دارد که کلید هر داده و Shard مربوط به آن را نگهداری میکند.
- سیستمی مانند یک نقشه دارد که میگوید: UserID = ۱۲۳۴۵ → Shard 2، UserID = ۹۸۷۶۵ → Shard 7.
Sharding جغرافیایی (Geographic Sharding)
دادهها بر اساس محل کاربران یا مشتریان در Shardهای مختلف ذخیره میشوند.
- کاربران اروپا در Shard مستقر در دیتاسنتر آلمان، کاربران آسیا در Shard مستقر در سنگاپور و کاربران آمریکا در Shard دیتاسنتر ایالات متحده.
Sharding ترکیبی (Hybrid Sharding)
در سیستمهای بزرگ، معمولاً ترکیبی از چند روش بالا استفاده میشود.
- یک شبکه اجتماعی ممکن است ابتدا کاربران را بر اساس منطقه جغرافیایی شارد کند و سپس داخل هر منطقه از روش Hash-Based استفاده کند.
یک مثال برای درک بهتر Sharding
برای درک بهتر، فرض کنید یک فروشگاه اینترنتی بزرگ مانند آمازون یا دیجیکالا را در نظر بگیریم. در چنین فروشگاههایی، میلیونها کاربر روزانه جستجو و خرید انجام میدهند. اگر همهی دادهها در یک پایگاه داده ذخیره شوند، با افزایش حجم سفارشها و تراکنشها، سیستم به سرعت با مشکل مواجه خواهد شد.
راهکار Sharding این است که به عنوان نمونه، کاربران هر استان یا منطقه به یک Shard اختصاص یابند. به این ترتیب، کاربران تهران به Shard مربوط به تهران متصل میشوند و کاربران اصفهان به Shard مخصوص اصفهان. این تقسیمبندی سبب میشود پردازشها سریعتر انجام شوند و فشار کاری بین پایگاههای داده مختلف توزیع شود.
از منظر شبکه نیز میتوان Sharding را مشابه با Load Balancing در نظر گرفت؛ با این تفاوت که در Load Balancing، ترافیک شبکه میان چند سرور توزیع میشود، در حالی که در Sharding دادهها میان چند پایگاه داده تقسیم خواهند شد.
جمعبندی
Sharding در اصل راهکاری برای شکستن محدودیتهای پایگاهدادههای متمرکز است. وقتی حجم داده یا تعداد کاربران به حدی میرسد که یک سرور یا حتی یک خوشهی ساده پاسخگو نیست، تقسیم دادهها بین چندین Shard باعث مقیاسپذیری افقی، افزایش کارایی، کاهش تأخیر و ایزوله شدن خطاها میشود.





نشانی ایمیل شما منتشر نخواهد شد. بخشهای موردنیاز علامتگذاری شدهاند *
نظر دهید تعداد کاراکتر مانده: 300